Uber开发了一种新的分布式计算库Fibe
Uber 开发了 POET、Go-Explore 和 GTN 等算法,这些算法利用大量的计算来训练神经网络模型。为了使未来几代类似算法的大规模计算成为可能,Uber 进而开发了一种新的分布式计算库 Fiber,它可以帮助用户轻松地将本地计算方法扩展到成百上千台机器上。Fiber 可以使使用 Python 的大规模计算项目变得快速、简单和资源高效,从而简化 ML 模型训练过程,并获得更优的结果。
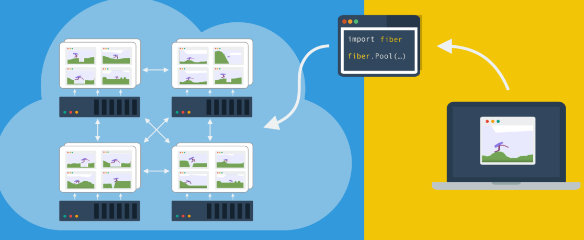
在过去的几年中,计算机不断增强的处理能力推动了机器学习的进步。算法越来越多地利用并行性,并依赖分布式训练来处理大量数据。然而,随之而来的是增加数据和训练的需求,这对管理和利用大规模计算资源的软件提出了巨大的挑战。
在 Uber,我们开发了 POET 、 Go-Explore 和 GTN 等算法,这些算法利用大量的计算来训练神经网络模型。为了使未来几代类似算法的大规模计算成为可能,我们开发了一种新的分布式计算库 Fiber ,它可以帮助用户轻松地将本地计算方法扩展到成百上千台机器上。Fiber 可以使使用 Python 的大规模计算项目变得快速、简单和资源高效,从而简化 ML 模型训练过程,并获得更优的结果。
大规模分布式计算的挑战
在理想情况下,将运行在一台机器上的应用程序扩展为运行在一批机器上的应用程序应该很容易,只需更改命令行参数即可。然而,在现实世界中,这并不容易。
我们每天都与许多运行大规模分布式计算任务的人一起工作,我们发现,现在很难利用分布式计算的原因有以下几个:
在笔记本或台式机本地运行代码与在生产集群上运行代码之间存在着巨大的差距。你可以让 MPI 在本地运行,但在计算机集群上运行它是完全不同的过程。
不能动态扩展。如果你启动了一个需要大量资源的作业,那么你很可能需要等待,直到所有资源都分配好了才可以运行该作业。这个等待降低了扩展的效率。
错误处理缺失。在运行时,有些作业可能会失败。你可能不得不还原部分结果或整个地放弃本次运行。
学习成本很高。每个系统都有不同的 API 和编程约定。要使用新系统启动作业,用户必须学习一套全新的约定。
新的 Fiber 平台专门解决了这些问题。它为更广泛的用户群体提供了无缝使用大规模分布式计算的可能。
Fiber 简介
Fiber 是一个用于现代计算机集群的基于 Python 的分布式计算库。用户可以利用这个系统针对整个计算机集群进行编程,而不是只针对单个台式机或笔记本电脑。它最初是为了支持像 POET 这样的大规模并行科学计算项目而开发的,Uber 也已经用它来支持类似的项目。Fiber 的功能非常强大,这样主要是因为:
易于使用。Fiber 允许用户编写在计算机集群上运行的程序,而不需要深入研究计算机集群的细节。
易于学习。Fiber 提供了与 Python 标准多处理库相同的 API。知道如何使用多处理库的工程师可以很容易地用 Fiber 编写计算机集群程序。
快速可靠。Fiber 的通信中枢基于 Nanomsg 构建,这是一个高性能异步消息传递库,可以提供快速、可靠的通信。
不需要部署。Fiber 在计算机集群上的运行方式与普通应用程序相同。它会自动为用户处理资源分配和通信。
提供了可靠的计算。Fiber 内置的错误处理功能让用户可以专注于编写实际的应用程序代码,而不是处理崩溃问题。当运行一个工作进程池时,这尤其有价值。
除了这些好处之外,Fiber 还可以在特别关注性能的领域与其他专用框架搭配使用。例如,对于随机梯度下降(SGD),Fiber 的 Ring 特性可以帮助我们在计算机集群上建立分布式训练作业,并允许它与 Horovod 或 torch.distributed 协同。
Uber 正式开源分布式机器学习平台 Fiber
图 1:Fiber 启动许多不同的作业支持(job-backed)进程,然后在其中运行不同的 Fiber 组件和用户进程。Fiber Master 是管理所有其他进程的主进程。有些进程(如 Ring Node)保持成员之间的通信。
Fiber 可以帮助从事大规模分布式计算的用户减少从产生想法到在计算集群上实际运行分布式作业的时间。它还可以帮助用户屏蔽配置和资源分配任务的繁琐细节,并且可以缩短调试周期,简化从本地开发到集群开发的转换。
架构
Fiber 让我们可以灵活地为经典的多处理 API 选择可以在不同集群管理系统上运行的后端。为了实现这种集成,Fiber 被分为三个不同的层:API 层、后端层和集群层。API 层为 Fiber 提供了进程、队列、池和管理器等基本构建块。它们具有与多处理相同的语义,但是我们对它们进行扩展了,使它们可以在分布式环境中工作。后端层处理在不同集群管理器上创建或终止作业的任务。当用户新增一个后端时,所有其他 Fiber 组件(队列、池等)都不需要更改。最后,集群层由不同的集群管理器组成。尽管它们不是 Fiber 本身的一部分,但是它们帮助 Fiber 管理资源并跟踪不同的作业,减少了 Fiber 所需要跟踪的项的数量。图 2 是总体架构图:
Fiber 的架构包括 API 层、后端层和集群层,这让它可以在不同的集群管理系统上运行。
作业支持进程
Fiber 引入了一个新的概念,称为作业支持过程(也称为 Fiber 进程)。这些进程与 Python 多处理库中的进程类似,但是更灵活:多处理库中的进程只在本地机器上运行,但 Fiber 进程可以在不同的机器上远程运行,也可以在同一机器上本地运行。当新的 Fiber 进程启动时,Fiber 会在当前计算机集群上创建一个具有适当 Fiber 后端的新作业。
Fiber 中的每个作业支持进程都是在计算机集群上运行的一个容器化作业。每个作业支持进程也有自己的 CPU、GPU 和其他计算资源。在容器内运行的代码是自包含的。
Fiber 使用容器来封装当前进程的运行环境(如上图 3 所示),其中包括所有必需的文件、输入数据和其他依赖的程序包,而且要保证每个元素都是自包含的。所有子进程都以与父进程相同的容器镜像启动,以确保运行环境的一致性。因为每个进程都是一个集群作业,所以它的生命周期与集群上的任何作业相同。为了方便用户,Fiber 被设计成直接与计算机集群管理器交互。因此,不像 Apache Spark 或 ipyparallel ,Fiber 不需要在多台机器上设置,也不需要通过任何其他机制引导。它只需要作为一个普通的 Python pip 包安装在一台机器上。
组件
Fiber 基于 Fiber 进程实现了大多数多处理 API,包括管道、队列、池和管理器。
Fiber 中队列和管道的行为方式与多处理相同。不同之处在于,Fiber 中的队列和管道由运行在不同机器上的多个进程共享。两个进程可以从同一个管道读取和写入数据。此外,队列可以在不同机器上的多个进程之间共享:Fiber 可以在不同的 Fiber 进程之间共享队列。在本例中,一个 Fiber 进程与队列位于同一台机器上,另外两个进程位于另一台机器上。一个进程写入队列,另外两个进程读取队列。
Fiber 也支持池,如下图 5 所示。它们让用户可以管理工作进程池。Fiber 使用作业支持进程扩展池,以便每个池可以管理数千个(远程)工作进程。用户还可以同时创建多个池。
:在具有三个工作进程的池中,如本例所示,两个工作进程位于一台机器上,另一个位于另一台机器上。它们共同处理提交到主进程中任务队列的任务,并将结果发送到结果队列。
管理器和代理对象使 Fiber 能够支持共享存储,这在分布式系统中至关重要。通常,这个功能由计算机集群外部存储系统如 Cassandra 和 Redis 提供。相反,Fiber 为应用程序提供了内置的内存存储。该接口与多处理系统中的管理器类型接口相同。
Ring 是对多处理 API 的扩展,可以用于分布式计算设置。在 Fiber 中,Ring 指的是一组共同工作的、相对平等的进程。与池不同,Ring 没有主进程和辅助进程的概念。Ring 内的所有成员承担大致相同的责任。Fiber 的 Ring 模型拓扑(如下图 6 所示)在机器学习分布式 SGD 中非常常见, torch.distributed 和 Horovod 就是例子。一般来说,在一个计算机集群上启动这种工作负载是非常具有挑战性的;Fiber 提供 Ring 特性就是为了帮助建立这样的拓扑。
Uber 正式开源分布式机器学习平台 Fiber
图 6:在一个有四个节点的 Fiber Ring 中,Ring 节点 0 和 Ring 节点 3 运行在同一台机器上,但在两个不同的容器中。Ring 节点 1 和节点 2 都在单独的机器上运行。所有这些进程共同运行同一函数的副本,并在运行期间相互通信。
应用程序
借助上述灵活的组件,我们现在可以使用 Fiber 构建应用程序了。在这一节中,我们将展示两种使用 Fiber 帮助用户构建分布式应用程序的方式。
赋能新应用程序
在下面的例子中,我们将展示工程师如何运用 Fiber 来实现大规模分布式计算。这个例子演示的是一个强化学习(RL)算法。通常,分布式 RL 的通信模式涉及在机器之间发送不同类型的数据,包括动作、神经网络参数、梯度、per-step/episode 观察及奖励。
Fiber 实现了管道和池来传输这些数据。在底层,池是普通的 Unix 套接字,为使用 Fiber 的应用程序提供接近线路速度的通信。现代计算机网络的带宽通常高达每秒几百千兆。通过网络传输少量数据通常速度很快。
此外,如果有许多不同的进程向一个进程发送数据,进程间通信延迟也不会增加太多,因为数据传输可以并行进行。事实证明,Fiber 池可以作为许多 RL 算法的基础,因为模拟器可以在各个池工作进程中运行,并且结果可以并行回传。
免责声明:本文由用户上传,与本网站立场无关。财经信息仅供读者参考,并不构成投资建议。投资者据此操作,风险自担。 如有侵权请联系删除!
-
【成熟男人试探你心意的表现】在感情中,一个成熟的男人往往不会直接表达自己的情感,而是通过一些细微的行为...浏览全文>>
-
【成熟男人励志网名大全】在当今社会,越来越多的男性开始注重个人形象与精神世界的塑造。一个富有力量感和正...浏览全文>>
-
【成熟男人合适的网名】在当今网络世界中,一个合适的网名不仅能体现个人风格,还能传递出一种沉稳、自信的气...浏览全文>>
-
【成熟男人的微信网名】在当今社交网络日益普及的时代,微信已经成为人们日常交流的重要工具。一个合适的微信...浏览全文>>
-
【成熟男人的网名大全】在互联网世界中,一个合适的网名不仅能够体现一个人的性格和气质,还能传递出一种沉稳...浏览全文>>
-
【成熟男人的网名】在当今网络世界中,网名不仅是个人身份的象征,更是个性与气质的体现。对于成熟男人来说,...浏览全文>>
-
【成熟男人的四个字网名大全】在当今网络社交中,一个合适的网名不仅能体现个人风格,还能传达出一种气质与内...浏览全文>>
-
【成熟男人的经典说说】在人生的旅途中,成熟的男人往往有着独特的思考方式和处世态度。他们不轻易表露情绪,...浏览全文>>
-
【成熟蜜和不成熟蜜如何区别】在蜂蜜市场中,消费者常常会遇到“成熟蜜”与“不成熟蜜”的说法。这两者虽然都...浏览全文>>
-
【成熟简短的微信网名】在如今的社交网络中,一个合适的微信网名不仅能体现个人风格,还能传达出一种成熟稳重...浏览全文>>