人类具有识别他人情感的能力。尽管机器人和虚拟代理完全具备通过语音与人进行通信的能力,但它们仅擅长处理逻辑指令,这极大地限制了人机交互(HRI)。因此,HRI的大量研究都是关于语音情感识别的。但是首先,我们如何描述情绪?
我们已经很好地理解了诸如幸福,悲伤和愤怒之类的情感,但是机器人很难记录这些情感。研究人员专注于“维数情感”,它构成了自然语言中的渐进式情感过渡。“持续的多维情感可以帮助机器人捕捉说话者情感状态的时间动态,并相应地实时调整其互动和内容的方式,”科学技术研究院(JAIST)的Masashi Unoki教授解释说。关于语音识别和处理。
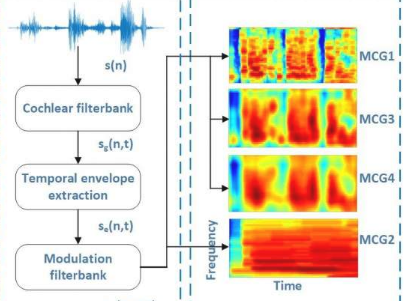
研究表明,模拟人耳工作的听觉感知模型可以生成所谓的“时间调制提示”,它可以忠实地捕捉维度情感的时间动态。然后可以使用神经网络从这些提示中提取反映这些时间动态的特征。然而,由于听觉感知模型的复杂性和多样性,特征提取变得非常具有挑战性。
在神经网络上发表的一项新研究中,Unoki教授及其同事包括来自天津大学的彭志超(领导该研究),来自彭城实验室的当建武党和来自JAIST的Masato Akagi教授,现在从认知神经科学的最新发现中获得的灵感表明,我们的大脑通过对频谱-时间调制的组合分析,形成了具有不同频谱(即频率)和时间分辨率的自然声音的多种表示形式。
因此,研究人员提出了一种称为多分辨率调制滤波耳蜗图(MMCG)的新功能,该功能将四个分辨率不同的调制滤波耳蜗图(输入声音的时频表示)组合在一起,以获得时间和上下文调制提示。为了说明耳蜗图的多样性,研究人员设计了一种称为“长短期记忆”(LSTM)的并行神经网络体系结构,该体系结构对耳蜗图的多分辨率信号的时间变化进行了建模,并对两个耳蜗图的数据集进行了广泛的实验。自发的讲话。
结果令人鼓舞。研究人员发现,对于这两个数据集,MMCG的情感识别性能均明显优于传统的基于声学的特征和其他基于听觉的特征。此外,与基于LSTM的简单方法相比,并行LSTM网络显示了对尺寸情感的出色预测。
Unoki教授很高兴,并打算在未来的研究中改进MMCG功能。他总结说:“我们的下一个目标是分析环境噪声源的鲁棒性,并研究我们在其他任务上的功能,例如分类情感识别,语音分离和语音活动检测。”