听力损失是一个快速发展的科学研究领域,因为随着年龄的增长,处理听力损失的婴儿潮一代人数不断增加。为了了解听力损失如何影响人们,研究人员研究了人们识别语音的能力。如果存在混响、某些听力障碍或显着的背景噪音(例如交通噪音或多个扬声器),人们将更难以识别人类语音。
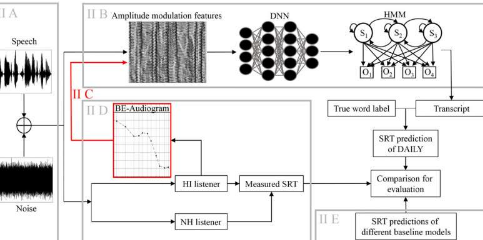
因此,助听器算法经常被用来改善人类语音识别。为了评估此类算法,研究人员进行了旨在确定识别特定数量单词(通常为 50%)的信噪比的实验。然而,这些测试是时间和成本密集型的。
在美国声学学会杂志上,来自德国的研究人员探索了一种基于机器学习和深度神经网络的人类语音识别模型。
“我们模型的新颖之处在于,它为听力受损的听众提供了对复杂性非常不同的噪声类型的良好预测,并显示出低误差和与测量数据的高度相关性,”来自 Carl Von Ossietzky 大学的作者 Jana Roßbach 说。
研究人员使用自动语音识别(ASR)计算了听众每个句子能理解多少个单词。大多数人通过 Alexa 和 Siri 等语音识别工具熟悉 ASR。
该研究由 8 名听力正常的听众和 20 名听力受损的听众组成,他们暴露在各种复杂的噪音中,这些噪音掩盖了讲话。听力受损的听众被分为三组,具有不同程度的与年龄相关的听力损失。
该模型使研究人员能够预测具有不同听力损失程度的听力受损听众的人类语音识别性能,这些噪声掩蔽器在时间调制和与真实语音的相似性方面越来越复杂。一个人可能的听力损失可以单独考虑。
“我们最惊讶的是,预测对所有噪声类型都有效。我们预计该模型在使用单个竞争说话者时会出现问题。但事实并非如此,”Roßbach 说。
该模型对单耳听力进行了预测。展望未来,研究人员将开发一个双耳模型,因为理解语音会受到双耳听力的影响。
除了预测语音清晰度之外,该模型还可能用于预测听力努力或语音质量,因为这些主题非常相关。